O email de phishing parecia perfeitamente rotineiro. Um alegado pedido de escalada de um fornecedor, com um link para um documento partilhado. A analista SOC de serviço hesitou um instante, acabou por clicar a partir do browser local e disparou de imediato um credential harvester que se propagou às caixas de correio da equipa financeira. Qualquer analista tem uma história parecida, porque analisar links suspeitos faz parte do trabalho e a pressão para dar respostas rápidas nunca dá tréguas.
Fazer análise segura de um link já não passa por arrancar uma VM cheia de pó e ficar à espera que o malware se porte bem lá dentro. As ameaças atuais usam exploits de browser, payloads fileless e fingerprinting para fugir de sandboxes mal montadas. Este guia leva-te por um fluxo de trabalho que te permite investigar URLs com calma e, ao mesmo tempo, deixar documentado tudo o que a tua chefia vai pedir.
Como é o fluxo de trabalho moderno do analista
Investigar um link deixou de ser uma tarefa de segunda linha. As equipas maduras tratam-no como uma linha de montagem, com checkpoints definidos, recolha de dados e controlos. Perceber as três fases torna evidente onde é que o isolamento faz mesmo a diferença.
Receção e contexto. Recolhe os headers originais do email, o contexto do ticket e tudo o que houver sobre a pessoa que reportou. Regista quem clicou, em que equipamento e há quantos minutos. É esta base que te permite refazer o caminho caso a investigação se alargue. À saída ficas com uma cópia do payload da URL, os anexos de apoio e a SLA acordada.
Execução controlada. Só abres a URL dentro de uma sessão de browser descartável e isolada. Grava o ecrã, os fluxos de rede e os downloads em automático. Nunca leves artefactos de volta para a máquina local. À saída ficas com um transcript de sessão, as primeiras notas de comportamento e os ficheiros descarregados, guardados do lado do servidor à espera da detonação.
Enriquecimento e correlação. Cruza com os feeds de threat intelligence, manda detonar os ficheiros recolhidos em sandbox e compara os indicadores com incidentes anteriores. Junta as anotações do analista aos resultados automáticos. À saída ficas com uma lista de IOCs, uma pontuação de risco e as ações de contenção recomendadas.
Porque é que os setups clássicos falham
Os analistas recorrem muitas vezes a VMs locais ou a portáteis «sujos» dedicados. Os atacantes conhecem bem estes hábitos e aproveitam as brechas. Há três tipos de falha que se repetem sempre.
Snapshots ultrapassados. As VMs offline ganham pó. As patches em falta e um antivírus desatualizado criam precisamente as vulnerabilidades que querias observar. O malware atual identifica estes ambientes por fingerprinting e muda de comportamento, ou fica-se mesmo pela fuga. Segundo um relatório, 64 % das red teams conseguiram sair de VMs de analista nos exercícios tabletop de 2025.
Artefactos que ficam pelo caminho.Históricos de ligação, credenciais em cache e relatórios por cifrar vão-se acumulando nas máquinas dos analistas. Quem faz incident response encontra com frequência cookies ou scripts maliciosos sobrantes de investigações anteriores. Segundo o inquérito SOC 2025 da Gartner, 37 % das equipas admitiram ter encontrado artefactos maliciosos nos próprios endpoints dos seus analistas.
O peso do reset manual. Reinstalar um equipamento ou repor um snapshot consome tempo que os analistas simplesmente não têm. Sob pressão, as equipas saltam essa etapa. O resultado é contaminação cruzada entre casos e uma cadeia de evidência cheia de buracos. Um browser virtual inverte o modelo: cada clique acontece num ambiente limpo que se autodestrói assim que fechas o separador. Nem fingerprint para tranquilizar o malware, nem persistência com que te preocupares.
Um ambiente de análise seguro
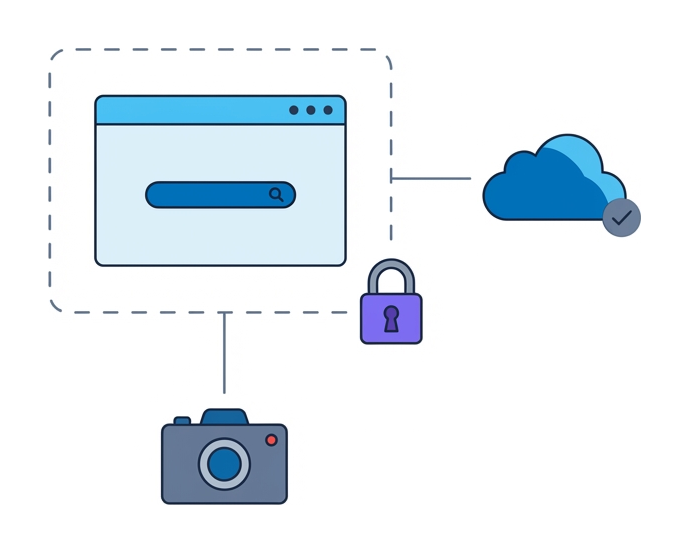
Encara o teu setup como um stack: contenção de rede, execução descartável, captura forense. Cada camada tem uma única função e o stack só se aguenta com as três presentes.
Contenção de rede. Encaminha todo o tráfego por um ponto de egress isolado com filtragem apertada. O browser isolation trata disso em automático: só os píxeis seguem em stream para a analista, enquanto as chamadas de rede ficam dentro da cloud do fornecedor. O que precisas é de suporte para DNS personalizado, safe-listing e captura de pacotes, sem nunca expor os IPs dos analistas.
Execução limpa. Cada sessão deve arrancar a partir de um contentor acabado de sair da fábrica, sem cache partilhada nem estado de sessão. O teardown automático torna impossível qualquer persistência depois de a investigação encerrar. Ter triggers de API que lançam sessões com as ferramentas já pré-carregadas (consola de developer, inspetor de rede, screenshots) poupa tempo a cada caso.
Captura de evidência. Recolhe em automático logs HTTP, snapshots do DOM e gravações de sessão. Guarda tudo num sítio central, para que os analistas possam trocar casos entre si ou voltar à evidência durante as post-incident reviews. Confirma que o formato de exportação se integra bem com o teu SIEM e com as ferramentas de case management, não apenas com a interface do próprio fornecedor.
Um processo de investigação repetível
Usa este runbook sempre que um link suspeito te aparecer na fila. Tira o palpite do meio e devolve a consistência que os auditores gostam de ver.
- 1
Arrancar uma sessão isolada
Abre um contentor novo. Confirma que a gravação está ativa e anota o ID da sessão no ticket antes de tocares sequer na URL. - 2
Inspecionar a URL antes do clique
Passa por cima do link para ver o destino, expande os URL shorteners e faz passive DNS lookups. Tira screenshots do email ou da mensagem que está a empurrar para o clique. - 3
Interagir com método
Clica devagar. Toma nota de redirecionamentos, conteúdos carregados dinamicamente e requests de formulário. Usa as developer tools para inspecionar os scripts à medida que vão a carregar. - 4
Extrair indicadores
Copia domínios suspeitos, endereços IP, hashes de ficheiros e payloads POST para as tuas notas de trabalho. Só dispares downloads se tiveres uma sandbox pronta a jusante. - 5
Desmontar e escalar
Fecha a sessão para destruir o contentor, anexa os logs de sessão ao ticket e escala com uma recomendação clara: bloquear, monitorizar ou ignorar.
Indicadores a recolher
Saber o que recolher é meio caminho andado. As duas categorias que os analistas costumam cobrir a menos são os sinais de infraestrutura e os sinais de comportamento.
Sinais de infraestrutura: domínio final de aterragem, ASN de alojamento, emissor do certificado SSL, endereços IP dos redirect hops e respetiva geolocalização, registos DNS (A, CNAME, MX) e antiguidade do registo, mais quaisquer serviços de CDN ou proxy que estejam a tapar a origem. Dão-te a saber onde está alojada a campanha.
Sinais de comportamento: campos de formulário que pedem credenciais ou códigos MFA, avisos de download com os respetivos content-type headers, eventos JavaScript que disparam em blur, submit ou keypress e chamadas API de saída para infraestrutura de ameaça conhecida. Dão-te a saber o que a campanha está mesmo a tentar fazer aos utilizadores.
Das conclusões à threat intelligence
Notas soltas não servem para nada se não chegarem aos sistemas que os teus stakeholders usam todos os dias. Transforma cada investigação num artefacto de intelligence que outras pessoas possam aproveitar.
Começa por um mini-relatório: impacto no utilizador, nível de confiança da deteção, ações recomendadas e lista de IOCs. Junta-lhe os screenshots de apoio. Deixa-o num sítio onde IR e liderança o encontrem depressa. Empurra os indicadores para o SIEM com tags de contexto para nome de campanha, threat actor e geografia. Se têm uma threat intelligence platform, publica o evento com as etiquetas TLP que façam sentido.
Volta atrás à equipa de suporte frontline que abriu o ticket. Um resumo curto por escrito a explicar o que vigiar da próxima vez é uma das atividades com mais retorno que um SOC pode fazer e quase sempre acaba a ficar para trás porque está toda a gente a abarrotar de trabalho.
Integração com o SOC
O melhor fluxo de trabalho desmorona-se assim que depende de heroísmos individuais. Encaixa o processo dentro do próprio tooling do SOC e empurra a cultura para «isolar sempre, documentar sempre».
Automatiza o arranque das sessões. Um botão dentro do próprio ticketing que abre um separador de investigação Browser.lol já marcado com o ID do incidente acaba com o copy-paste entre consolas e faz do fluxo de trabalho o caminho de menor resistência.
Define à partida os critérios de escalada. Deixa por escrito os limiares a partir dos quais um analista passa o caso para incident response: harvesting de credenciais confirmado, download de malware, ligações a operadores de ransomware conhecidos. Esta clareza prévia evita tanto a escalada a mais como a escalada a menos nos momentos de pressão.
Faz post-incident reviews todas as semanas. Passa uma gravação de sessão durante o sync do SOC e discutam pontos de decisão, lacunas de tooling e se o isolamento apanhou alguma coisa que o EDR deixou passar. Estas reviews servem ao mesmo tempo de formação e de feedback para o produto.
As métricas que contam
Quem gere quer números, não anedotas. Acompanha três métricas com sinal forte e terás argumentos sólidos para qualquer renovação.
dos links suspeitos ficaram contidos dentro de sessões isoladas
de redução no tempo médio para qualificar uma URL suspeita
endpoints de analista a reinstalar depois das investigações
Os números exatos variam de organização para organização, mas o padrão é claro. O isolamento desloca o centro de gravidade: a contenção sobe, o tempo de investigação desce e o número de limpezas posteriores tende para zero.
Começa hoje mesmo a usar este fluxo de trabalho
O próximo link suspeito já está na caixa de entrada de alguém. Passar para browsers isolados e descartáveis mantém os teus analistas em segurança e, ao mesmo tempo, gera intelligence mais rica para quem está do lado da defesa.
Dá à tua equipa um único clique para iniciar investigações, capturar tudo em automático e fechar cada caso com endpoints limpos. Browser.lol transforma a curiosidade arriscada em experiências sob controlo.
Pronto para teres um desktop completo em qualquer dispositivo?
Experimenta o Browser.lol grátis e sente a produtividade de um PC a partir do telemóvel.
Abrir o meu navegador desktopSem instalações • Funciona em qualquer dispositivo