El correo de phishing tenía toda la pinta de ser rutinario. Una supuesta escalada de un proveedor, con un enlace a un documento compartido. La analista SOC de guardia dudó un instante y acabó haciendo clic desde su browser local, disparando en el acto un credential harvester que se propagó hasta los buzones del equipo de finanzas. Cualquier analista tiene una historia parecida, porque revisar enlaces sospechosos forma parte del trabajo y la presión por responder rápido no afloja nunca.
Analizar un enlace de forma segura ya no consiste en arrancar una VM llena de polvo y cruzar los dedos para que el malware se quede quieto dentro. Las amenazas actuales se apoyan en exploits de browser, payloads fileless y fingerprinting para escapar de sandboxes mal montadas. Esta guía te lleva paso a paso por un workflow que te permite investigar URLs con tranquilidad mientras dejas documentado todo lo que tu dirección te va a pedir.
Cómo es el workflow moderno del analista
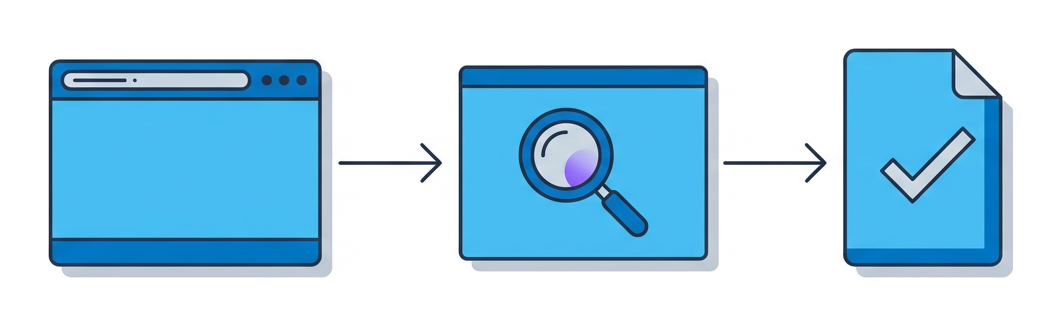
Investigar un enlace ha dejado de ser una tarea secundaria. Los equipos maduros la operan como una cadena de montaje, con checkpoints definidos, captura de datos y controles. Entender las tres fases deja claro en qué puntos el aislamiento marca más la diferencia.
Recepción y contexto. Recupera los headers originales del correo, el contexto del ticket y cuanta información tengas sobre quien reportó. Anota quién hizo clic, en qué equipo y hace cuántos minutos. Esa base es lo que te permite reconstruir el recorrido si la investigación se amplía. Como resultado obtienes una copia del payload de la URL, los adjuntos relevantes y la SLA comprometida.
Ejecución controlada. Abre la URL únicamente dentro de una sesión de browser desechable y aislada. Graba pantalla, flujos de red y descargas de forma automática. No te lleves nunca artefactos a tu equipo local. Como resultado obtienes un transcript de sesión, las primeras notas de comportamiento y los ficheros descargados, almacenados en el servidor a la espera de detonación.
Enriquecimiento y correlación.Cruza la información con tus feeds de threat intelligence, detona los ficheros capturados en sandbox y compara los indicadores con incidentes anteriores. Fusiona las anotaciones del analista con los resultados automáticos. Como resultado obtienes una lista de IOCs, una puntuación de riesgo y las acciones de contención recomendadas.
Por qué fallan los setups clásicos
Los analistas suelen recurrir a VMs locales o a portátiles «sucios» dedicados. Los atacantes conocen estos patrones al dedillo y aprovechan los huecos. Hay tres tipos de fallo que se repiten una y otra vez.
Snapshots desfasados. Las VMs offline acaban cubiertas de polvo. Los parches pendientes y un antivirus que va por detrás crean justo las vulnerabilidades que en teoría querías observar. El malware moderno detecta esos entornos por fingerprinting y cambia de comportamiento, o se larga por completo. Según un informe, el 64 % de los red teams logró escapar de VMs de analista en los ejercicios tabletop de 2025.
Artefactos que se quedan colgados.Historiales de conexión, credenciales en caché e informes sin cifrar se acumulan en los equipos de los analistas. Quienes hacen incident response encuentran a menudo cookies o scripts maliciosos que han sobrevivido a investigaciones anteriores. Según la encuesta SOC 2025 de Gartner, el 37 % de los equipos reconoció haber encontrado artefactos maliciosos en los endpoints de sus propios analistas.
La carga del reset manual. Reinstalar equipos o restaurar snapshots consume un tiempo que los analistas no tienen. Bajo presión, los equipos se saltan ese paso. El resultado es contaminación cruzada entre casos y una cadena de evidencia con agujeros. Un browser virtual le da la vuelta al modelo. Cada clic ocurre en un entorno limpio que se autodestruye al cerrar la pestaña. Ni fingerprints que tranquilicen al malware ni persistencia de la que preocuparse.
Un entorno de análisis seguro
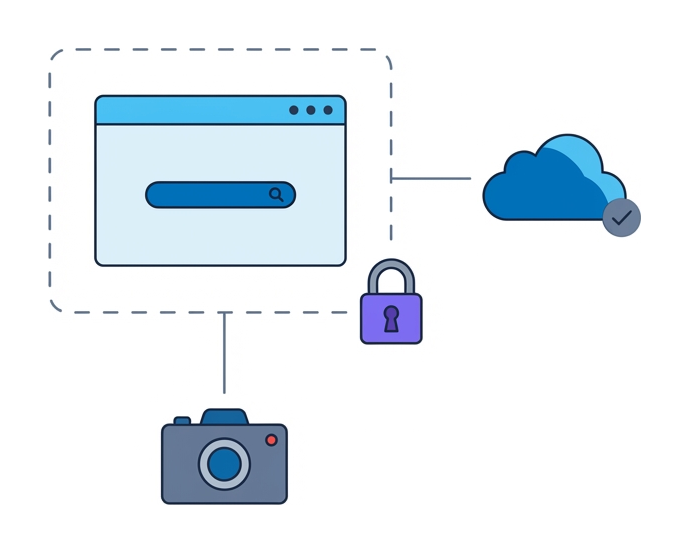
Piensa tu montaje como un stack: contención de red, ejecución desechable, captura forense. Cada capa tiene una sola función y el stack solo se sostiene si están las tres.
Contención de red. Encamina todo el tráfico por un punto de egress aislado con filtrado estricto. El aislamiento de browser se encarga de ello de forma automática: solo los píxeles llegan al analista, mientras las llamadas de red se quedan dentro del cloud del proveedor. Lo que necesitas es soporte de DNS personalizado, safe-listing y capturas de paquetes, todo sin exponer las IPs de los analistas.
Ejecución limpia. Cada sesión debería arrancar desde un contenedor recién salido de fábrica, sin caché compartida ni estado de sesión. El teardown automatizado hace imposible cualquier persistencia una vez cerrada la investigación. Disponer de triggers de API que lancen sesiones con las herramientas ya cargadas (consola de desarrollador, inspector de red, capturas) ahorra tiempo en cada caso.
Captura de evidencia. Recoge en automático logs HTTP, snapshots del DOM y grabaciones de sesión. Almacénalo todo en un sitio centralizado para que los analistas puedan pasarse los casos o volver a la evidencia en los post-incident reviews. Comprueba que el formato de exportación encaja bien con tu SIEM y con tus herramientas de case management, no solo con la interfaz propia del proveedor.
Un proceso de investigación repetible
Usa este runbook siempre que un enlace sospechoso aterrice en tu cola. Quita el pálpito de la ecuación y deja la consistencia que los auditores quieren ver.
- 1
Lanzar una sesión aislada
Abre un contenedor nuevo. Comprueba que la grabación está activa y deja anotado el ID de sesión en el ticket antes de tocar la URL. - 2
Inspeccionar la URL antes de hacer clic
Pasa el cursor por encima del enlace para ver el destino, despliega los URL shorteners y lanza passive DNS lookups. Captura screenshots del correo o del mensaje que invita al clic. - 3
Interactuar con método
Haz clic con calma. Anota redirecciones, cargas dinámicas de contenido y peticiones de formulario. Tira de las developer tools para inspeccionar los scripts a medida que se cargan. - 4
Extraer indicadores
Copia dominios sospechosos, direcciones IP, hashes de ficheros y payloads POST a tus notas de trabajo. Dispara las descargas solo si tienes una sandbox lista detrás. - 5
Desmontar y escalar
Cierra la sesión para destruir el contenedor, adjunta los logs de sesión al ticket y escala con una recomendación clara: bloquear, monitorizar o ignorar.
Indicadores que hay que capturar
Saber qué hay que recoger ya es medio trabajo hecho. Las dos categorías que los analistas tienden a recoger de menos son las señales de infraestructura y las señales de comportamiento.
Señales de infraestructura: dominio final de aterrizaje, ASN de hosting, emisor del certificado SSL, direcciones IP de los redirect hops y su geolocalización, registros DNS (A, CNAME, MX) y antigüedad del registro, más cualquier servicio CDN o proxy que tape el origen. Te dicen dónde está alojada la campaña.
Señales de comportamiento: campos de formulario que piden credenciales o códigos MFA, avisos de descarga con sus content-type headers, eventos JavaScript que saltan al blur, submit o keypress y llamadas API salientes hacia infraestructura de amenaza conocida. Te muestran qué pretende hacer la campaña con los usuarios en la práctica.
De los hallazgos a la threat intelligence
Las notas en bruto no sirven de gran cosa mientras no acaben en los sistemas que usan tus stakeholders. Convierte cada investigación en un artefacto de inteligencia que otros equipos puedan aprovechar.
Empieza por un mini-informe: impacto en el usuario, nivel de confianza de la detección, acciones recomendadas y lista de IOCs. Adjunta las capturas de apoyo. Déjalo en un sitio donde los equipos de IR y dirección lo encuentren a la primera. Empuja los indicadores al SIEM con tags de contexto de nombre de campaña, threat actor y geografía. Si tenéis una threat intelligence platform, publica el evento con las etiquetas TLP que correspondan.
Vuelve al equipo de soporte de primera línea que abrió el ticket. Un resumen breve por escrito sobre qué vigilar la próxima vez es una de las actividades de mayor retorno que puede hacer un SOC, y casi siempre se queda en el tintero porque todo el mundo va al límite.
Integración con el SOC
El mejor workflow se viene abajo si depende de heroicidades. Embebe el proceso dentro del propio tooling del SOC y desplaza la cultura hacia «siempre aislar, siempre documentar».
Automatiza el arranque de las sesiones. Un botón dentro del propio sistema de ticketing que abra una pestaña de investigación de Browser.lol pre-etiquetada con el ID del incidente elimina el copy-paste entre consolas y convierte el workflow en el camino de menor resistencia.
Define los criterios de escalado de antemano. Documenta los umbrales a partir de los cuales un analista pasa un caso a incident response: harvesting de credenciales confirmado, descarga de malware, conexiones a operadores de ransomware conocidos. Tener esto claro de entrada evita tanto el exceso como la falta de escalado en los momentos de estrés.
Haz post-incident reviews cada semana. Reproduce una grabación de sesión durante el sync del SOC y comenta los puntos de decisión, las carencias de tooling y si el aislamiento atrapó algo que el EDR dejó pasar. Estas revisiones son a la vez formación y feedback para el producto.
Las métricas que importan
A los directivos lo que les interesa son los números, no las anécdotas. Sigue tres métricas con señal y tendrás argumentos para cada renovación.
de los enlaces sospechosos quedaron contenidos dentro de sesiones aisladas
de reducción en el tiempo medio para cualificar una URL sospechosa
endpoints de analista que hubo que reinstalar tras las investigaciones
Los números exactos cambian de una organización a otra, pero el patrón es lo que importa. El aislamiento desplaza el centro de gravedad: la contención sube, el tiempo de investigación baja y las limpiezas posteriores tienden a cero.
Empieza a usar este workflow hoy mismo
El próximo enlace sospechoso ya está en la bandeja de entrada de alguien. Pasarse a browsers aislados y desechables mantiene a salvo a tus analistas y, a la vez, produce inteligencia más rica para tu equipo de defensa.
Dale a tu equipo un único clic para lanzar investigaciones, capturarlo todo en automático y cerrar cada caso con endpoints limpios. Browser.lol convierte la curiosidad arriesgada en experimentos bajo control.
Llévate un escritorio entero a cualquier dispositivo
Prueba Browser.lol gratis y trabaja como en un PC desde el móvil.
Abrir mi navegador en la nubeSin descargas • Funciona en cualquier dispositivo